L’entreprise spécialisée dans les véhicules avec chauffeur se vante de savoir qui a eu une aventure d’un soir.
Les anglo-saxons appellent cela le « walk of shame », « la marche de la honte », le trajet qui sépare son appartement de celui de son partenaire d’une nuit : quelqu’un rentre chez lui/elle, mal rasé ou sans maquillage, tôt le matin après avoir passé une partie de la nuit chez un/une partenaire rencontré(e) dans un bar, une soirée… Bradley Voytek préfère, lui, parler de « ride of glory » (trajet de la gloire).
Le plus troublant, c’est que Bradley Voytek est data evangelist (il promeut l’analyse des données) pour Uber, l’application qui permet de commander une voiture avec chauffeur. Et que Bradley Voytek se vante de pouvoir utiliser les données collectées par les ordinateurs de cette entreprise pour savoir qui a eu une aventure d’un soir… Sur le blog qu’il tient pour Uber, Bradley Voytek s’est livré à une longue analyse des « rides of glory » dans six villes américaines, démontrant leur augmentation en fin de semaine (le samedi matin et le dimanche matin) et, dans l’année, par exemple au moment du Tax Day (date limite, vers le 15 avril, aux Etats-Unis pour remplir sa déclaration de revenus ; certains Américains reçoivent alors un remboursement de la part du Fisc…). En revanche, le nombre de « rides of glory » s’effondre à l’approche de la Saint Valentin…
Dans un message précédent, Bradley Voytek avait même établi une corrélation, toujours grâce aux données collectées par Uber, entre le versement des chèques d’allocation et de la Sécurité sociale (les deuxième, troisième et quatrième mercredis du mois, aux Etats-Unis) et la fréquentation des prostituées.
Bien sûr, pour ses calculs, Bradley Voytek n’utilise que des données anonymisées. Mais avant d’être anonymisées, ces données correspondent à des cas réels dont elles révèlent toute la vie. Lors des réunions que les dirigeants d’Uber organisent avant l’ouverture de leur service dans une nouvelle ville, ces responsables auraient même utilisé un logiciel maison, baptisé « God view » (« Ce que voit Dieu », tout un programme…) pour montrer à leur assistance qu’ils pouvaient suivre en direct les déplacements de leurs clients… Ce qui constitue, bien sûr, une violation de la vie privée (sauf dans de très rare cas où cela serait justifié par des nécessités de service ou de sécurité).
Toutes ces informations sont remontées la surface à la suite d’une récente polémique opposant une journaliste de San Fransisco et un cadre d’Uber, qui se disait prêt à espionner la vie privée de cette dernière (dont il ne supporte pas les articles qu’elle consacre à son entreprise).
Au-delà de cette polémique, le plus choquant est, bien sûr, l’extrême indiscrétion des données collectées (par exemple, qui a fait un « walk of shame » et donc une rencontre d’une nuit, selon Uber) par une simple application sur un smartphone. Un sénateur américain vient d’ailleurs d’écrire aux dirigeants d’Uber pour leur demander des éclaircissements sur l’utilisation des données qu’ils collectent.
Si nous n’apprenons pas aujourd’hui à nos enfants à maîtriser leurs données, à faire respecter leur vie privée, demain ce sont les données des autres, qu’ils seront sans doute conduits à manipuler dans le cadre de leur travail, qu’ils ne respecteront pas. Et les outils formidables que constituent les nouvelles technologies pourraient bien donner naissance à une dictature numérique mondiale.
Devenus adultes, les ados d’aujourd’hui travailleront peut-être dans l’analyse des données, un métier en plein essor. Si nous ne les aidons pas, maintenant, à faire respecter, sur Facebook, leur intimité et à respecter celle de leurs amis, ils risquent fort de ne pas acquérir de bons réflexes en termes de défense de la vie privée. Et de conserver ces comportements dans leur travail, où ils seront justement conduits à manipuler des données personnelles. Les conséquences pourraient être catastrophiques sur les libertés individuelles.
Adam D. I. Kramer, Jamie E. Guillory et Jeffrey T. Hancock – photos extraites de leurs profils Facebook ou Linkedin
Trois brillants trentenaires américains, Adam D. I. Kramer, «data scientist» (data scientifique ou chargé de modélisation des données) au service « Recherche » de Facebook, Jamie E. Guillory, chercheuse postdoctorale à l’université de San Francisco, et Jeffrey T. Hancock, professeur à l’université Cornell (Ithaca, état de New York), ont publié le 17 juin 2014 une étude intitulée « Preuve expérimentale de contagion émotionnelle à grande échelle par l’intermédiaire des réseaux sociaux » (« Experimental evidence of massive-scale emotional contagion through social networks »).
Ces trois titulaires d’un doctorat (en communication pour la jeune femme et en psychologie pour ses deux collègues) y affirment avoir modifié les contenus vus par 689 003 utilisateurs, consultant Facebook en anglais, du 11 au 18 janvier 2012 ; ils voulaient prouver que plus un internaute voyait de messages négatifs sur ce réseau, plus il aurait tendance à publier lui-même des messages négatifs ; inversement avec les messages positifs.
Les résultats de ce travail doivent être relativisés, puisque seulement 0,1% à 0,07% des internautes auraient modifié leur comportement. Mais sa révélation a, fort justement, suscité un tollé dans le monde entier : certes Facebook n’a rien à se reprocher sur le plan légal (1), mais avait-il le droit moral de manipuler ses utilisateurs ?
Voilà trois jeunes gens bardés de diplômes qui n’ont pas réfléchi aux conséquences de leurs agissements. Comment le pourraient-ils ? Voilà des années qu’ils dévoilent leur vie sur les réseaux sociaux : Jeffrey T. Hancock et Jamie E. Guillory utilisent Facebook depuis 2004, et Adam D. I. Kramer, depuis 2007.
Ils pourraient servir de cobayes pour une étude validant la prophétie que Mark Zuckberg, le fondateur de Facebook, fit en 2010 : « la vie privée n’est plus une norme sociale.» Comment des jeunes gens, à qui ce réseau social a fait perdre la notion même de vie privée, pour eux, mais aussi pour les autres – ce qui leur a donc fait ôter une grande partie de ce qui constitue le respect d’autrui-, pourraient-ils avoir des remords en manipulant les informations envoyées à des internautes ?
Voilà bien ce qui risque d’arriver si nous n’ouvrons pas les yeux de nos adolescents sur le modèle économique des sites Internet gratuits comme les réseaux sociaux (ils revendent nos données à des entreprises, sous formes de publicité) et si nous ne les sensibilisons pas au respect de la vie privée, entre autres en leur montrant comment paramétrer correctement leur profil Facebook : devenus adultes, s’ils travaillent sur des données personnelles, ils risquent de ne pas les estimer à leur juste valeur.
Or, ces données sont aussi précieuses que les êtres humains qu’elles représentent, puisqu’elles en constituent le « double numérique ».
Schématiquement, on peut dire que l’analyse de cette quantité d’informations incroyables à laquelle l’humanité a désormais accès, constitue ce que l’on appelle le « Big Data » ; l’objectif du « Big Data » étant de trouver, au sein de ces données, des corrélations (des règles), qui vont expliquer des phénomènes jusqu’ici mystérieux. Puis de s’en servir pour réaliser des prédictions : quel traitement va le mieux marcher sur tel malade ? quelle pièce sur tel modèle d’avion assemblé telle année dans telle usine présente un risque de « casser » ? ou qui a le plus de chance de voter pour tel candidat (3) ?
Voici ce qu’a répondu Stéphane Mallat, 50 ans, mathématicien, professeur à l’Ecole Normale Supérieure de Paris, lorsque j’ai demandé si les scientifiques n’avaient pas l’impression, avec le Big Data, de jouer avec le feu :«[…] un outil scientifique, on le sait très bien, on peut l’utiliser à des objectifs qui peuvent être complètement différents. Une roue, ça peut servir à faire un char de guerre tout comme à transporter de la nourriture. C’est absolument clair que les outils de Big Data peuvent avoir des effets nocifs de surveillance et il faut pouvoir le contrôler, donc là, c’est à la société d’établir des règles et surtout d’abord de comprendre la puissance pour pouvoir adapter la législation, les règles à l’éthique. A partir de là, en même temps, il faut bien réaliser qu’avec ces outils, on est capable de potentiellement considérablement améliorer la médecine, notamment en définissant des cures qui ne sont plus adaptées à un groupe de population, mais à une personne en fonction de son génome de son mode de vie.[…] Donc ce que je pense, c’est que c’est un outil extraordinairement riche et ensuite, c’est à nous tous en termes de société de s’assurer qu’il est utilisé à bon escient. (4) »
Commençons par éduquer nos ados au respect de leur propre vie privée.
___
(1) La Politique d’utilisation des données de Facebook précise « […] nous pouvons utiliser les informations que nous recevons à votre sujet : […] pour des opérations internes, dont le dépannage, l’analyse de données, les tests, la recherche et l’amélioration des services.» (2) Victor Mayer-Schönberger, Kenneth Cukier, « Big Data A revolution that will transform how we live, work and think», Hougthon Mifflin Harcourt, Boston New York, 2013 p. 15 (3) voir mon livre « Silicon Valley / Prédateurs Vallée ? Comment Apple, Facebook, Google et les autres s’emparent de nos données » (4) le phénomène Big Data, Les fondamentales (CNRS), La Sorbonne, 15 novembre 2013, à réécouter sur http://ift.tt/1snUCUo (je pose ma question 1H05 après le début du débat).
Devenus adultes, les ados d’aujourd’hui travailleront peut-être dans l’analyse des données, un métier en plein essor. Si nous ne les aidons pas, maintenant, à faire respecter, sur Facebook, leur intimité et à respecter celle de leurs amis, ils risquent fort de ne pas acquérir de bons réflexes en termes de défense de la vie privée. Et de conserver ces comportements dans leur travail, où ils seront justement conduits à manipuler des données personnelles. Les conséquences pourraient être catastrophiques sur les libertés individuelles.
Adam D. I. Kramer, Jamie E. Guillory et Jeffrey T. Hancock – photos extraites de leurs profils Facebook ou Linkedin
Trois brillants trentenaires américains, Adam D. I. Kramer, «data scientist» (data scientifique ou chargé de modélisation des données) au service « Recherche » de Facebook, Jamie E. Guillory, chercheuse postdoctorale à l’université de San Francisco, et Jeffrey T. Hancock, professeur à l’université Cornell (Ithaca, état de New York), ont publié le 17 juin 2014 une étude intitulée « Preuve expérimentale de contagion émotionnelle à grande échelle par l’intermédiaire des réseaux sociaux » (« Experimental evidence of massive-scale emotional contagion through social networks »).
Ces trois titulaires d’un doctorat (en communication pour la jeune femme et en psychologie pour ses deux collègues) y affirment avoir modifié les contenus vus par 689 003 utilisateurs, consultant Facebook en anglais, du 11 au 18 janvier 2012 ; ils voulaient prouver que plus un internaute voyait de messages négatifs sur ce réseau, plus il aurait tendance à publier lui-même des messages négatifs ; inversement avec les messages positifs.
Les résultats de ce travail doivent être relativisés, puisque seulement 0,1% à 0,07% des internautes auraient modifié leur comportement. Mais sa révélation a, fort justement, suscité un tollé dans le monde entier : certes Facebook n’a rien à se reprocher sur le plan légal (1), mais avait-il le droit moral de manipuler ses utilisateurs ?
Voilà trois jeunes gens bardés de diplômes qui n’ont pas réfléchi aux conséquences de leurs agissements. Comment le pourraient-ils ? Voilà des années qu’ils dévoilent leur vie sur les réseaux sociaux : Jeffrey T. Hancock et Jamie E. Guillory utilisent Facebook depuis 2004, et Adam D. I. Kramer, depuis 2007.
Ils pourraient servir de cobayes pour une étude validant la prophétie que Mark Zuckberg, le fondateur de Facebook, fit en 2010 : « la vie privée n’est plus une norme sociale.» Comment des jeunes gens, à qui ce réseau social a fait perdre la notion même de vie privée, pour eux, mais aussi pour les autres – ce qui leur a donc fait ôter une grande partie de ce qui constitue le respect d’autrui-, pourraient-ils avoir des remords en manipulant les informations envoyées à des internautes ?
Voilà bien ce qui risque d’arriver si nous n’ouvrons pas les yeux de nos adolescents sur le modèle économique des sites Internet gratuits comme les réseaux sociaux (ils revendent nos données à des entreprises, sous formes de publicité) et si nous ne les sensibilisons pas au respect de la vie privée, entre autres en leur montrant comment paramétrer correctement leur profil Facebook : devenus adultes, s’ils travaillent sur des données personnelles, ils risquent de ne pas les estimer à leur juste valeur.
Or, ces données sont aussi précieuses que les êtres humains qu’elles représentent, puisqu’elles en constituent le « double numérique ».
Schématiquement, on peut dire que l’analyse de cette quantité d’informations incroyables à laquelle l’humanité a désormais accès, constitue ce que l’on appelle le « Big Data » ; l’objectif du « Big Data » étant de trouver, au sein de ces données, des corrélations (des règles), qui vont expliquer des phénomènes jusqu’ici mystérieux. Puis de s’en servir pour réaliser des prédictions : quel traitement va le mieux marcher sur tel malade ? quelle pièce sur tel modèle d’avion assemblé telle année dans telle usine présente un risque de « casser » ? ou qui a le plus de chance de voter pour tel candidat (3) ?
Voici ce qu’a répondu Stéphane Mallat, 50 ans, mathématicien, professeur à l’Ecole Normale Supérieure de Paris, lorsque j’ai demandé si les scientifiques n’avaient pas l’impression, avec le Big Data, de jouer avec le feu :«[…] un outil scientifique, on le sait très bien, on peut l’utiliser à des objectifs qui peuvent être complètement différents. Une roue, ça peut servir à faire un char de guerre tout comme à transporter de la nourriture. C’est absolument clair que les outils de Big Data peuvent avoir des effets nocifs de surveillance et il faut pouvoir le contrôler, donc là, c’est à la société d’établir des règles et surtout d’abord de comprendre la puissance pour pouvoir adapter la législation, les règles à l’éthique. A partir de là, en même temps, il faut bien réaliser qu’avec ces outils, on est capable de potentiellement considérablement améliorer la médecine, notamment en définissant des cures qui ne sont plus adaptées à un groupe de population, mais à une personne en fonction de son génome de son mode de vie.[…] Donc ce que je pense, c’est que c’est un outil extraordinairement riche et ensuite, c’est à nous tous en termes de société de s’assurer qu’il est utilisé à bon escient. (4) »
Commençons par éduquer nos ados au respect de leur propre vie privée.
___
(1) La Politique d’utilisation des données de Facebook précise « […] nous pouvons utiliser les informations que nous recevons à votre sujet : […] pour des opérations internes, dont le dépannage, l’analyse de données, les tests, la recherche et l’amélioration des services.» (2) Victor Mayer-Schönberger, Kenneth Cukier, « Big Data A revolution that will transform how we live, work and think», Hougthon Mifflin Harcourt, Boston New York, 2013 p. 15 (3) voir mon livre « Silicon Valley / Prédateurs Vallée ? Comment Apple, Facebook, Google et les autres s’emparent de nos données » (4) le phénomène Big Data, Les fondamentales (CNRS), La Sorbonne, 15 novembre 2013, à réécouter sur http://ift.tt/1snUCUo (je pose ma question 1H05 après le début du débat).
La Cour de justice de l’Union européenne (CJUE) a rendu le 13 mai dernier une décision sur le « droit à l’oubli » : les moteurs de recherche comme Google devront répondre favorablement aux internautes qui souhaiteraient faire effacer des informations sur eux apparaissant sur des sites Web. Malheureusement, cette décision ne constitue qu’une première étape dans la défense de la vie privée. Au-delà des serveurs Internet qui révèlent des informations sur nous, il y a bien plus important à protéger : notre double numérique.
Quelque part dans le monde, à chaque instant, se créent des «doubles numériques» de nous-mêmes, à partir d’informations collectées sur Internet et/ou puisées dans des fichiers existants, contenant des informations parcellaires ou complètes, vraies ou fausses, actualisées ou anciennes, et pouvant être utilisés à des fins commerciales, policières, politiques ou d’espionnage économique.
Jacques Perriault a proposé dès 2003 «la notion de “double numérique” pour caractériser l’ensemble des données que les systèmes d’information recueillent stockent et traitent pour chaque individu [1]». Nous avons utilisé l’expression « double numérique » pour la première fois début 2006, pour parler des fichiers et des fichiers résultant des croisements de fichiers constitués à partir d’informations volontairement communiquées par les internautes-consommateurs-citoyens, mais aussi à partir d’informations collectées à l’insu de ces acteurs. Pour nous, un double numérique n’est donc pas constitué des traces que nous laissons, mais de l’interprétation (la transformation de l’information en savoir ou supposé tel) de ces traces.
Par exemple, lorsque l’utilisateur d’un “capteur de données” (comme le réseau social Facebook) crée son compte chez ce “capteur”, puis s’y connecte, il fournit à ce “capteur” : prénom, nom, date et lieu de naissance, centres d’intérêt, liste d’amis, date et heure de connexion, actualisation de son statut, photos publiées, clics sur des publicités, pages Web visitées contenant une “émanation” du capteur (bouton «J’aime» de Facebook), etc.
Le double numérique de cet utilisateur, compilé par le “capteur de données” (comme Facebook) pour un “marchand de données” (dans notre exemple les propres services commerciaux de Facebook), est souvent constitué d’une liste de centres d’intérêts déduits des données collectées. Cette liste de centre d’intérêts va permettre de classer cet individu dans tel ou tel profil publicitaire (cf. le concept de «database of intentions» de John Battelle [2]) :
Voici, par exemple, le double numérique, compilé par Facebook, d’une lycéenne de 17 ans [3], autrement dit les centres d’intérêts de cette jeune fille, en tout cas ce qu’en perçoit le réseau social :
Sujets publicitaires
#Venus
#Bookselling
#Book
#Million
#JC Lattès
#Whiskas
#Mario Vargas Llosa
#Francophone
#Paul Robert (lexicographer)
#Cat
#Leo Perutz
#French livre
#March
La fin de la vie privée ? Enjeux sociétaux, économiques et légaux des doubles numériques.
Les doubles numériques :
• peuvent révéler des pans entiers de la vie privée des internautes-consommateurs-citoyens, y compris des données sensibles (sexualité, préférences politiques…). Sur l’interface que le “capteur/marchand de données” Facebook met à la disposition de ses annonceurs, il est possiblede cibler des internautes en fonction d’intérêts supposés pour des drogues illégales ou des pratiques sexuelles [4].
• échappent partiellement ou totalement à la simple connaissance et encore plus au contrôle des individus ainsi “profilés”. Même si les utilisateurs des plateformes de socialisation décident de cacher telle ou telle information à leurs contacts, l’ensemble des informations qu’ils publient reste accessible aux programmes de profilage de ces plateformes. Les doubles numériques rendent donc plausible l’hypothèse de la fin de la vie privée, contrairement à ce que soutiennent, par exemple, Antonio A.Casilli [5] ou Isabelle Falque-Pierrotin, la présidente de la CNIL (Commission Nationale de l’Informatique et des Libertés) [6]. Si l’on retient comme définition de la vie privée, la possibilité de choisir les informations que l’on souhaite divulguer ou cacher à tels ou tels groupes de personnes [7], cette possibilité n’existe plus avec les doubles numériques.
• peuvent servir à influencer les comportements économiques ou politiques des individus, non seulement à travers des messages publicitaires, mais aussi en ne leur présentant que la partie d’un ensemble qui semble le mieux appropriée à leur double numérique, ce qui peut conduire à une distorsion de la perception de la réalité recherchée par l’utilisateur : le double numérique sert à nous montrer «ce qu’il pense que nous voulons voir [8]». Comment en sommes-nous arrivés à laisser des algorithmes décider de ce qui est bien pour nous ?
• constituent la première source de revenus de l’économie numérique [9]
• servent à surveiller les individus (concept de «dataveillance» de Roger Clarcke [10]) et alimentent une utopie de surveillance totale (projet américain TIA – Total Information Awareness – au lendemain des attentats du 11 septembre 2001 [11]). Utopie que la NSA tente de rendre réelle, comme l’ont montré les révélations de l’ancien consultant de la NSA Edward Snowden. Or, cette utopie remet en cause un des droits de l’homme communs à la plupart des démocraties modernes : «Tout homme étant présumé innocent jusqu’à ce qu’il ait été déclaré coupable […] [12] » ; et le transforme en «Tout individu peut être surveillé et est donc présumé suspect»
De la nécessité d’une recherche sur les doubles numériques
Les doubles numériques méritent donc d’être étudiés à travers les prismes d’au moins sept thèmes :
• “double numérique” et concept : pourquoi « double » plutôt que « simple » dimension supplémentaire d’être au monde et d’existence ? En quoi y a t il « double » plutôt qu’une nouvelle modalité de description des logiques d’actions, de relations, etc.;
• double numérique et dispositifs sociaux-numériques : description des processus de traçabilité et de profilage des utilisateurs qui permettent la création de ces «doubles numériques» ;
• double numérique et représentation de l’identité : «Apparaît un individu réifié devenant une chose manipulable» [ 13]. Le double numérique constitue-il pour l’homme une tentative ultime et désespérée – faute de pouvoir comprendre l’autre, voire de devenir l’autre – d’enfermer cet autre dans des espaces préconçus ? Quelles sont les conséquences de cette vision réductrice de l’homme (normalement, « […] la répétition la plus exacte, la plus stricte a pour corrélat le maximum de différence »[14]?) sur la doxa (« Ensemble des opinions communes aux membres d’une société et qui sont relatives à un comportement social ») des relations hommes-machines, machines-machines et éventuellement hommes-hommes ?
• double numérique et marchandisation des données : usages commerciaux, policiers et politiques qui peuvent être faits de ces doubles numériques et des abus que ces usages peuvent entraîner. Les doubles numériques, « dans le contexte de l’auto-constitution ontologique du client à partir de son commerce des objets et des services, de sa position dans l’espace-temps numérique à n dimensions, géolocalisé, et à partir de ses énoncés prescriptifs validés [15] » offrent de bien meilleures capacités de profilage que les cartes de paiement ou les cartes de fidélités.
• double numérique et influence : interactions entre les «doubles numériques» et les internautes-consommateurs-citoyens : influence des doubles numériques sur les internautes (en ne nous montrant que ce qu’ils pensent que nous voulons voir, les doubles numériques ne se donnent-ils pas raison ?) ; influence des internautes sur les doubles numériques (boucles d’apprentissage [16] mises au point par les doubles numériques pour améliorer le profilage des internautes en fonction des réactions de ces derniers aux propositions commerciales qui leur sont faites)
• double numérique et surveillance : remise en cause de la notion de vie privée ; remise en cause de la présomption d’innocence ; mais qui surveille qui ? « Avec la nouvelle donne technique, le contrôlé peut désormais avoir accès à des moyens de contrôle utilisés par le contrôleur. De surveillé, il peut devenir à son tour surveillant. [17] »
• double numérique et citoyenneté : perception des doubles numériques par les internautes-consommateurs-citoyens ; éducation des internautes-consommateurs-citoyens à la perception et à la défense de leurs doubles-numériques
• double numérique et propriété : comment reprendre le contrôle de nos données ? Certains experts militent pour un renforcement des législations existantes, d’autres pour un nouveau droit de la propriété des données ou pour de nouvelles technologies [18].
Conclusion
Dans un contexte de dissémination générale des nouvelles technologies, les doubles numériques remettent en cause les notions mêmes de vies privée, citoyenne et politique. Ils constituent donc un enjeu sociétal majeur dans les sociétés numériques et imposent de bousculer «les cloisonnements disciplinaires, en ouvrant de nouvelles voies de recherche, mais aussi en accompagnant de nouvelles formes d’expérimentation sociales, territoriales, éducatives ou cognitives [19] »
Bibliographie
[1] Perriault Jacques, 2009, «Traces numériques personnelles, incertitude et lien social», Traçabilité et réseaux, Hermès 53, CNRS Editions, avril 2009, Paris, p. 15.
[5] Casilli A. A. 2013, «Contre l’hypothèse de la « fin de la vie privée », La négociation de la privacy dans les médias sociaux, Revue Française des Sciences de l’Information et de la Communication N°3, 2013, http://rfsic.revues.org/630
[7] Nippert-Eng, Christina. 2010, Islands of Privacy, University of Chicago Press, Chicago, octobre, 416 pages
[8] Eli Pariser, 2011, The Filter Bubble: What the Internet Is Hiding from You, Penguin Press, New York
[9]voir, entre autres, Lafrance J.-P., 2013, «L’économie numérique : la réalité derrière le miracle des NTIC, Revue Française des Sciences de l’Information et de la Communication N°3, http://rfsic.revues.org/639
[13] Franck Renucci, Benoît Le Blanc et Samuel Lepastier, 2014, «Introduction générale», L’Autre n’est pas une donnée, Hermès 68, CNRS Editions, avril 2014, Paris, p. 12.
[14] Deleuze Gilles, 1968, Différence et répétition, PUF, Paris, p. 5
[15] Noyer Jean-Max, 2013, « Les vertiges de l’hyper-marketing : Data Mining et production sémiotique », Les débats du numériques, Presse des Mines, Paris, p. 61
[16] Argyris Chris, 1976, «Single-Loop and Double-Loop Models in Research on Decision Making», Administrative Science Quarterly, Vol. 21, No. 3, Johnson Graduate School of Management, Cornell University, Septembre, pp. 363-375 Accès internet : http://academic.udayton.edu/richardghere/igo%20ngo%20research/argyris.pdf
[17] Mattelart Armand, Vitalis André, 2014, Le profilage des populations – Du livret ouvrier au cybercontrôle, La Découverte, Paris, p. 205
[19] Maignien Yannick, 2013, «Quelles redistributions de pouvoirs autour des “automates sémantiques” ?», Les débats du numériques, Presse des Mines, Paris, p. 226
La Cour de justice de l’Union européenne (CJUE) a rendu le 13 mai dernier une décision sur le « droit à l’oubli » : les moteurs de recherche comme Google devront répondre favorablement aux internautes qui souhaiteraient faire effacer des informations sur eux apparaissant sur des sites Web. Malheureusement, cette décision ne constitue qu’une première étape dans la défense de la vie privée. Au-delà des serveurs Internet qui révèlent des informations sur nous, il y a bien plus important à protéger : notre double numérique.
Quelque part dans le monde, à chaque instant, se créent des «doubles numériques» de nous-mêmes, à partir d’informations collectées sur Internet et/ou puisées dans des fichiers existants, contenant des informations parcellaires ou complètes, vraies ou fausses, actualisées ou anciennes, et pouvant être utilisés à des fins commerciales, policières, politiques ou d’espionnage économique.
Jacques Perriault a proposé dès 2003 «la notion de “double numérique” pour caractériser l’ensemble des données que les systèmes d’information recueillent stockent et traitent pour chaque individu [1]». Nous avons utilisé l’expression « double numérique » pour la première fois début 2006, pour parler des fichiers et des fichiers résultant des croisements de fichiers constitués à partir d’informations volontairement communiquées par les internautes-consommateurs-citoyens, mais aussi à partir d’informations collectées à l’insu de ces acteurs. Pour nous, un double numérique n’est donc pas constitué des traces que nous laissons, mais de l’interprétation (la transformation de l’information en savoir ou supposé tel) de ces traces.
Par exemple, lorsque l’utilisateur d’un “capteur de données” (comme le réseau social Facebook) crée son compte chez ce “capteur”, puis s’y connecte, il fournit à ce “capteur” : prénom, nom, date et lieu de naissance, centres d’intérêt, liste d’amis, date et heure de connexion, actualisation de son statut, photos publiées, clics sur des publicités, pages Web visitées contenant une “émanation” du capteur (bouton «J’aime» de Facebook), etc.
Le double numérique de cet utilisateur, compilé par le “capteur de données” (comme Facebook) pour un “marchand de données” (dans notre exemple les propres services commerciaux de Facebook), est souvent constitué d’une liste de centres d’intérêts déduits des données collectées. Cette liste de centre d’intérêts va permettre de classer cet individu dans tel ou tel profil publicitaire (cf. le concept de «database of intentions» de John Battelle [2]) :
Voici, par exemple, le double numérique, compilé par Facebook, d’une lycéenne de 17 ans [3], autrement dit les centres d’intérêts de cette jeune fille, en tout cas ce qu’en perçoit le réseau social :
Sujets publicitaires
#Venus
#Bookselling
#Book
#Million
#JC Lattès
#Whiskas
#Mario Vargas Llosa
#Francophone
#Paul Robert (lexicographer)
#Cat
#Leo Perutz
#French livre
#March
La fin de la vie privée ? Enjeux sociétaux, économiques et légaux des doubles numériques.
Les doubles numériques :
• peuvent révéler des pans entiers de la vie privée des internautes-consommateurs-citoyens, y compris des données sensibles (sexualité, préférences politiques…). Sur l’interface que le “capteur/marchand de données” Facebook met à la disposition de ses annonceurs, il est possiblede cibler des internautes en fonction d’intérêts supposés pour des drogues illégales ou des pratiques sexuelles [4].
• échappent partiellement ou totalement à la simple connaissance et encore plus au contrôle des individus ainsi “profilés”. Même si les utilisateurs des plateformes de socialisation décident de cacher telle ou telle information à leurs contacts, l’ensemble des informations qu’ils publient reste accessible aux programmes de profilage de ces plateformes. Les doubles numériques rendent donc plausible l’hypothèse de la fin de la vie privée, contrairement à ce que soutiennent, par exemple, Antonio A.Casilli [5] ou Isabelle Falque-Pierrotin, la présidente de la CNIL (Commission Nationale de l’Informatique et des Libertés) [6]. Si l’on retient comme définition de la vie privée, la possibilité de choisir les informations que l’on souhaite divulguer ou cacher à tels ou tels groupes de personnes [7], cette possibilité n’existe plus avec les doubles numériques.
• peuvent servir à influencer les comportements économiques ou politiques des individus, non seulement à travers des messages publicitaires, mais aussi en ne leur présentant que la partie d’un ensemble qui semble le mieux appropriée à leur double numérique, ce qui peut conduire à une distorsion de la perception de la réalité recherchée par l’utilisateur : le double numérique sert à nous montrer «ce qu’il pense que nous voulons voir [8]». Comment en sommes-nous arrivés à laisser des algorithmes décider de ce qui est bien pour nous ?
• constituent la première source de revenus de l’économie numérique [9]
• servent à surveiller les individus (concept de «dataveillance» de Roger Clarcke [10]) et alimentent une utopie de surveillance totale (projet américain TIA – Total Information Awareness – au lendemain des attentats du 11 septembre 2001 [11]). Utopie que la NSA tente de rendre réelle, comme l’ont montré les révélations de l’ancien consultant de la NSA Edward Snowden. Or, cette utopie remet en cause un des droits de l’homme communs à la plupart des démocraties modernes : «Tout homme étant présumé innocent jusqu’à ce qu’il ait été déclaré coupable […] [12] » ; et le transforme en «Tout individu peut être surveillé et est donc présumé suspect»
De la nécessité d’une recherche sur les doubles numériques
Les doubles numériques méritent donc d’être étudiés à travers les prismes d’au moins sept thèmes :
• “double numérique” et concept : pourquoi « double » plutôt que « simple » dimension supplémentaire d’être au monde et d’existence ? En quoi y a t il « double » plutôt qu’une nouvelle modalité de description des logiques d’actions, de relations, etc.;
• double numérique et dispositifs sociaux-numériques : description des processus de traçabilité et de profilage des utilisateurs qui permettent la création de ces «doubles numériques» ;
• double numérique et représentation de l’identité : «Apparaît un individu réifié devenant une chose manipulable» [ 13]. Le double numérique constitue-il pour l’homme une tentative ultime et désespérée – faute de pouvoir comprendre l’autre, voire de devenir l’autre – d’enfermer cet autre dans des espaces préconçus ? Quelles sont les conséquences de cette vision réductrice de l’homme (normalement, « […] la répétition la plus exacte, la plus stricte a pour corrélat le maximum de différence »[14]?) sur la doxa (« Ensemble des opinions communes aux membres d’une société et qui sont relatives à un comportement social ») des relations hommes-machines, machines-machines et éventuellement hommes-hommes ?
• double numérique et marchandisation des données : usages commerciaux, policiers et politiques qui peuvent être faits de ces doubles numériques et des abus que ces usages peuvent entraîner. Les doubles numériques, « dans le contexte de l’auto-constitution ontologique du client à partir de son commerce des objets et des services, de sa position dans l’espace-temps numérique à n dimensions, géolocalisé, et à partir de ses énoncés prescriptifs validés [15] » offrent de bien meilleures capacités de profilage que les cartes de paiement ou les cartes de fidélités.
• double numérique et influence : interactions entre les «doubles numériques» et les internautes-consommateurs-citoyens : influence des doubles numériques sur les internautes (en ne nous montrant que ce qu’ils pensent que nous voulons voir, les doubles numériques ne se donnent-ils pas raison ?) ; influence des internautes sur les doubles numériques (boucles d’apprentissage [16] mises au point par les doubles numériques pour améliorer le profilage des internautes en fonction des réactions de ces derniers aux propositions commerciales qui leur sont faites)
• double numérique et surveillance : remise en cause de la notion de vie privée ; remise en cause de la présomption d’innocence ; mais qui surveille qui ? « Avec la nouvelle donne technique, le contrôlé peut désormais avoir accès à des moyens de contrôle utilisés par le contrôleur. De surveillé, il peut devenir à son tour surveillant. [17] »
• double numérique et citoyenneté : perception des doubles numériques par les internautes-consommateurs-citoyens ; éducation des internautes-consommateurs-citoyens à la perception et à la défense de leurs doubles-numériques
• double numérique et propriété : comment reprendre le contrôle de nos données ? Certains experts militent pour un renforcement des législations existantes, d’autres pour un nouveau droit de la propriété des données ou pour de nouvelles technologies [18].
Conclusion
Dans un contexte de dissémination générale des nouvelles technologies, les doubles numériques remettent en cause les notions mêmes de vies privée, citoyenne et politique. Ils constituent donc un enjeu sociétal majeur dans les sociétés numériques et imposent de bousculer «les cloisonnements disciplinaires, en ouvrant de nouvelles voies de recherche, mais aussi en accompagnant de nouvelles formes d’expérimentation sociales, territoriales, éducatives ou cognitives [19] »
Bibliographie
[1] Perriault Jacques, 2009, «Traces numériques personnelles, incertitude et lien social», Traçabilité et réseaux, Hermès 53, CNRS Editions, avril 2009, Paris, p. 15.
[5] Casilli A. A. 2013, «Contre l’hypothèse de la « fin de la vie privée », La négociation de la privacy dans les médias sociaux, Revue Française des Sciences de l’Information et de la Communication N°3, 2013, http://rfsic.revues.org/630
[7] Nippert-Eng, Christina. 2010, Islands of Privacy, University of Chicago Press, Chicago, octobre, 416 pages
[8] Eli Pariser, 2011, The Filter Bubble: What the Internet Is Hiding from You, Penguin Press, New York
[9]voir, entre autres, Lafrance J.-P., 2013, «L’économie numérique : la réalité derrière le miracle des NTIC, Revue Française des Sciences de l’Information et de la Communication N°3, http://rfsic.revues.org/639
[13] Franck Renucci, Benoît Le Blanc et Samuel Lepastier, 2014, «Introduction générale», L’Autre n’est pas une donnée, Hermès 68, CNRS Editions, avril 2014, Paris, p. 12.
[14] Deleuze Gilles, 1968, Différence et répétition, PUF, Paris, p. 5
[15] Noyer Jean-Max, 2013, « Les vertiges de l’hyper-marketing : Data Mining et production sémiotique », Les débats du numériques, Presse des Mines, Paris, p. 61
[16] Argyris Chris, 1976, «Single-Loop and Double-Loop Models in Research on Decision Making», Administrative Science Quarterly, Vol. 21, No. 3, Johnson Graduate School of Management, Cornell University, Septembre, pp. 363-375 Accès internet : http://academic.udayton.edu/richardghere/igo%20ngo%20research/argyris.pdf
[17] Mattelart Armand, Vitalis André, 2014, Le profilage des populations – Du livret ouvrier au cybercontrôle, La Découverte, Paris, p. 205
[19] Maignien Yannick, 2013, «Quelles redistributions de pouvoirs autour des “automates sémantiques” ?», Les débats du numériques, Presse des Mines, Paris, p. 226
La géolocalisation par Bluetooth, popularisée chez Apple sous le nom d’iBeacon, permet d’afficher sur un smartphone, selon l’endroit où se trouve son propriétaire, des informations personnalisées, avec une précision pouvant aller jusqu’à quelques centimètres. Ou de déclencher, sur ce même smartphone, l’ouverture d’une application.
Depuis quelques mois, les spécialistes s’enthousiasment pour ces petites balises Bluetooth et imaginent toutes sortes d’usages : promotions en magasin, domotique (gestion du chauffage quand vous quittez votre domicile…), déplacements (en entrant dans une gare, vous saurez de quel quai part votre TGV), localisation des objets (équipée d’une balise, votre valise s’annoncera en débarquant sur le tapis roulant de l’aéroport), jeu vidéo (l’ONU a utilisé des balises iBeacon pour simuler la présence de bombes antipersonnel lors d’une opération de sensibilisation à New York), médecine…
La géolocalisation par Bluetooth, popularisée chez Apple sous le nom d’iBeacon, permet d’afficher sur un smartphone, selon l’endroit où se trouve son propriétaire, des informations personnalisées, avec une précision pouvant aller jusqu’à quelques centimètres. Ou de déclencher, sur ce même smartphone, l’ouverture d’une application.
Depuis quelques mois, les spécialistes s’enthousiasment pour ces petites balises Bluetooth et imaginent toutes sortes d’usages : promotions en magasin, domotique (gestion du chauffage quand vous quittez votre domicile…), déplacements (en entrant dans une gare, vous saurez de quel quai part votre TGV), localisation des objets (équipée d’une balise, votre valise s’annoncera en débarquant sur le tapis roulant de l’aéroport), jeu vidéo (l’ONU a utilisé des balises iBeacon pour simuler la présence de bombes antipersonnel lors d’une opération de sensibilisation à New York), médecine…
Je participe ce soir, jeudi 15 août 2013, à l’émission «Le téléphone sonne» sur France Inter, de 19H20 à 20H, consacré à «Internet et réseaux sociaux, sommes-nous tous traqués et fichés ?[1]», aux côtés d’Etienne Drouard (avocat spécialiste de la protection de la vie privée, ancien membre de la CNIL), Mickaël Vuillaume (web analyste) et Jérémie Zimmermann (porte-parole de l’association la Quadrature du Net).
Les médias se sont fait l’écho de l’enquête ouverte fin juin par la CNIL (Commission Nationale de l’Informatique et des Libertés) et la DGCCRF (Direction Générale de la Concurrence, de la Consommation et de la Répression des Fraudes)[2] sur l’IP Tracking.
L’IP Tracking consisterait à repérer les ordinateurs des internautes qui recherchent des billets sur les sites de compagnies aériennes ou ferroviaires ; s’ils n’achètent pas tout de suite, mais reviennent un peu plus tard sur ces sites consulter les mêmes voyages, les prix sont augmentés pour inciter ces internautes à payer tout de suite.
Si elle était avérée, cette pratique commerciale pourrait être considérée comme déloyale[3] par la DGCCRF. De son côté, la CNIL se pose «la question de la loyauté de la collecte des données permettant de mettre en œuvre l’IP Tracking. Cette pratique serait opérée à l’insu des personnes et sans qu’elles soient en mesure de connaître, voire d’agir sur les mécanismes conduisant à moduler le tarif affiché.[4]»
Malheureusement le manque de loyauté de la collecte de données risque, je le crains, d’être difficile à prouver. En effet, l’IP Tracking s’effectue au moyen de cookies, des petits logiciels espions que les sites Web installent sur les navigateurs des internautes. Or, normalement, en Europe, tous les sites doivent informer leurs visiteurs qu’ils utilisent des cookies et leur demander leur accord avant de les installer sur leurs ordinateurs[5].
Une petite application – Ghostery[6] – permet de voir tous les cookies qui s’installent sur votre ordinateur lorsque vous arrivez sur un site.
Saisie d'écran du site de France Inter. Ghostery affiche en haut à droite les 14 cookies que ce site a enregistrées sur mon ordinateur
Ces cookies constituent des identifiants uniques qui permettent de savoir que tel ordinateur s’est rendu sur telle page de tel site Web. Ils contiennent souvent l’adresse IP de l’ordinateur (un numéro unique attribué en général par votre FAI – Fournisseur d’Accès à Internet), l’url des sites visités, une date d’expiration…
Ces cookies sont utilisés pour suivre à la trace les déplacements des Internautes à l’intérieur d’un même site ou au cours de leurs pérégrinations sur le Web, de serveurs en serveurs. C’est grâce à ces cookies que l’on peut connaître le nombre de visiteurs d’un site ou que nous n’avons pas besoin de retaper notre mot de passe lorsque nous revenons sur un site sur lequel nous nous sommes déjà identifiés.
Surtout, c’est grâce à ces petits logiciels espions que Google et les autres géants de la publicité en ligne nous affichent, sur leurs propres sites, mais aussi les sites dont ils assurent la régie publicitaire, des publicités dites « comportementales », car ciblées en fonction de notre comportement, de notre navigation sur Internet. Pour schématiser, ces régies publicitaires savent que notre ordinateur s’est d’abord rendu sur un site consacré aux couches-culottes, puis sur un site spécialisé dans les voitures familiales, avant un site dédié au crédit, et en déduisent que nous sommes à la recherche d’un crédit automobile. Elles vont donc nous afficher une pub pour un crédit automobile. Cette bannière correspondant à nos centres d’intérêts, nous allons cliquer dessus, ce qui va rapporter plus d’argent à Google et consorts.
Si vous souhaitez en savoir plus, je mets à votre disposition une petite vidéo expliquant le fonctionnement de la publicité comportementale[7].
Si vous souhaitez connaître dans quelles catégories publicitaires Google vous a classé, rendez vous sur http://www.google.com/intl/fr/policies/technologies/ads/ ; vers le milieu de cette page, vous trouverez un paragraphe intitulé
«Comment contrôler les cookies publicitaires» et qui commence par «Les paramètres des annonces permettent de gérer les annonces Google que vous voyez». Cliquez sur paramètres des annonces
Il existe plusieurs formes de publicités comportementales. L’une d’elles s’appelle le retargeting (reciblage). Elle consiste à utiliser les cookies pour suivre les internautes qui visitent un site marchand, mettent un produit dans leur panier, mais ne l’achètent pas. Pendant plusieurs jours, ils se verront proposer une publicité pour ce même produit. L’IP Tracking pourrait être considéré comme une variante du retargeting : on suit les internautes qui n’achètent pas et lorsqu’ils reviennent, on augmente le prix du produit qui les intéresse.
Inconvénient des cookies : on ne sait pas exactement qui est derrière l’ordinateur. On sait juste que c’est tel ordinateur qui visite tel site. C’est pourquoi Google, par exemple, nous pousse de plus en plus à nous identifier en utilisant un de ses services. En ce sens, le réseau social Google + avec 500 millions d’inscrits[8] est un succès pour le célèbre moteur de recherche. Une fois que je me suis inscrit sur un service Google (courrier électronique Gmail, site de partage de photo Picasa, réseau social Google +, YouTube…), les cookies de Google peuvent me suivre partout et accumuler autant d’informations sur moi.
Google se rapproche ainsi de Facebook, qui nous cible en fonction de notre graphe social (notre réseau d’amis sur Facebook), de nos publications, des sites que nous visitons et qui comportent un bouton «J’aime» de Facebook… Facebook accumule ainsi des données très indiscrètes sur nous (voir à ce sujet la polémique que j’ai soulevée sur le ciblage que Facebook propose en fonction de nos centres d’intérêts supposés pour certaines pratiques sexuelles ou des drogues illicites[9]).Pour savoir dans quelles catégories publicitaires Facebook vous a classé, suivez ce lien : http://tousfiches.blogspot.fr/2013/01/comment-savoir-dans-quelles-categories.html
Il existe d’autres techniques pour suivre à la trace les déplacements des Internautes sur le Web (par exemple, les pixels espions). Mais, à ce jour, la forme de publicité comportementale la plus aboutie fonctionne sur les smartphones : nous les avons en permanence sur nous et ils révèlent donc notre position.
Encadré : Yield Management
Petit rappel : les compagnies aériennes et ferroviaires pratiquent toutes le yield management (gestion fine des capacités) : pour optimiser le remplissage de leurs avions et de leurs trains, elles font fluctuer leur prix en fonction de la demande. Un voyageur, qui réserve un billet d’avion six mois à l’avance, paiera moins cher que quelqu’un qui réserve la veille du départ. La compagnie aérienne suppose que ce dernier veut absolument partir ce jour-là et qu’il est donc prêt à payer plus cher.
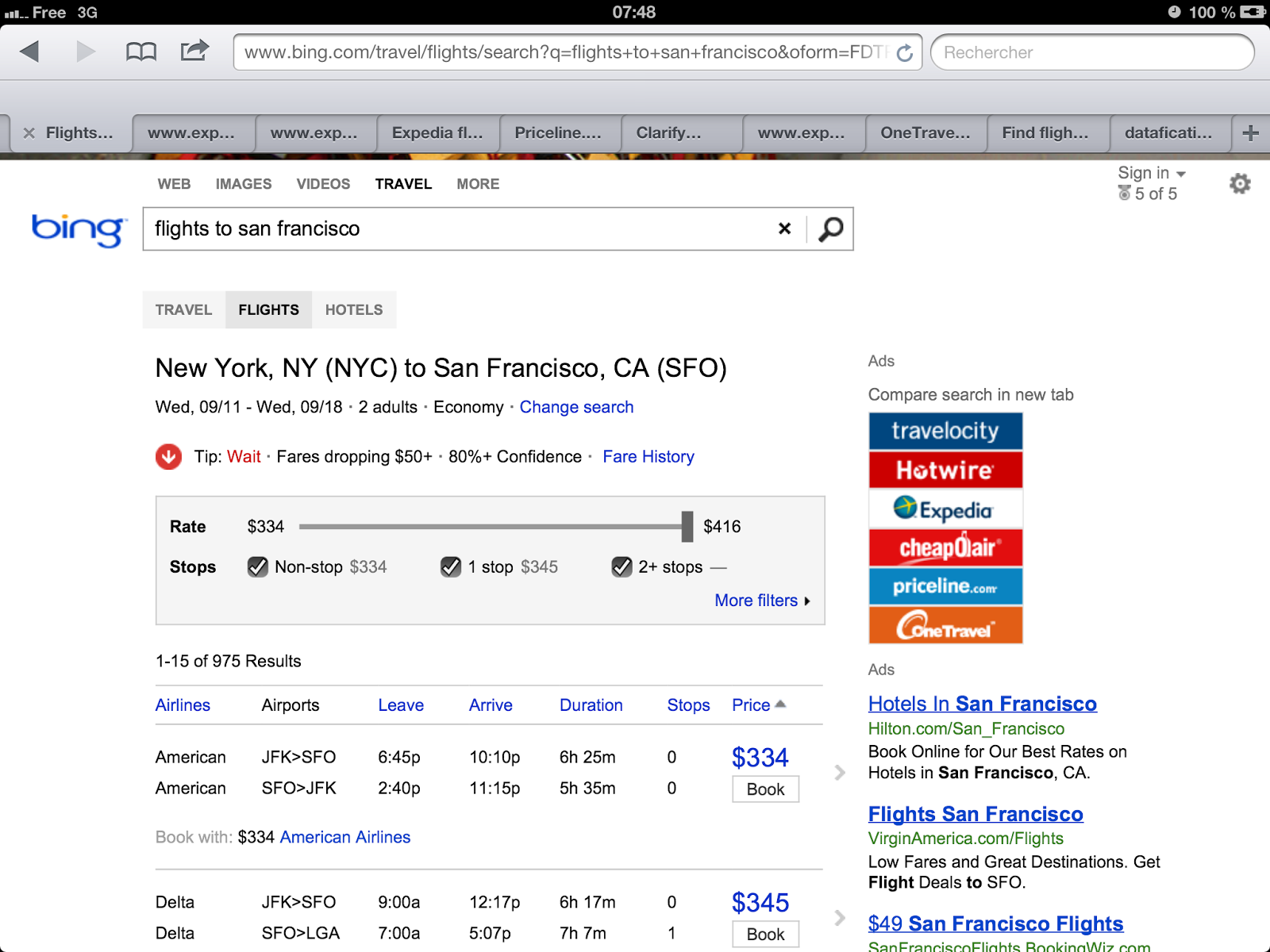
Aux Etats-Unis, le moteur de recherche Bing propose un outil qui permet de savoir s’il vaut mieux acheter son billet tout de suite, car il a forte probabilité d’augmenter dans les prochains jours, ou s’il vaut mieux attendre qu’il baisse.
[3] L’article L.120-1 du code de la consommation, considère comme déloyales une pratique commerciale «lorsqu’elle est contraire aux exigences de la diligence professionnelle et qu’elle altère, ou est susceptible d’altérer de manière substantielle, le comportement économique du consommateur normalement informé et raisonnablement attentif et avisé, à l’égard d’un bien ou d’un service.»
• Mardi 11 juin, j’ai été l’invité du journal de 18H de Tara Schlegel, pour parler du scandale Prism, le système d’espionnage américain, révélé par Edward Snowden ; vous pouvez réécouter mon intervention en suivant ce lien :
• Jeudi 13 juin, je suis intervenu pendant Les Choix de France Info, l’émission de Jean Leymarie, pour parler de nos «Données personnelles : quelles traces laissons-nous ?», à réécouter sur :
• Mardi 11 juin, j’ai été l’invité du journal de 18H de Tara Schlegel, pour parler du scandale Prism, le système d’espionnage américain, révélé par Edward Snowden ; vous pouvez réécouter mon intervention en suivant ce lien :
• Jeudi 13 juin, je suis intervenu pendant Les Choix de France Info, l’émission de Jean Leymarie, pour parler de nos «Données personnelles : quelles traces laissons-nous ?», à réécouter sur :
Internet, téléphone mobile, jeux vidéo… la révolution numérique affecte toute notre vie
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRejectRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.










{kind=link}
{kind=link}